
I am postdoctoral researcher at King Abdullah University of Science and Technology (KAUST) working with Prof. Bernard Ghanem. I completed my Phd at the University of Amsterdam, advised by Prof. Cees Snoek. My area of interest is Video Understanding, with my PhD thesis (which you can find here ) focussing on Video-Efficient Foundation Models. I am particularly interested in training foundation models via self-supervised learning from multiple modalities of the video data.
Contact: fida.thoker *at* kaust.edu.sa
News & Activities
- March 2026 : 'TrackMAE: Video Representation Learning via Track Mask and Predict' is accepted to CVPR
- March 2025 : 'SMILE: Infusing Spatial and Motion Semantics in Masked Video Learning' is accepted to CVPR
- September 2024 : 'LocoMotion: Learning Motion-Focused Video-Language Representations' is accepted as ACCV Oral
- July: Our paper 'SIGMA: Sinkhorn-Guided Masked Video Modeling' is accepted to ECCV
- May: I gave a talk at SkatingVerse Workshop , International Conference on Automatic Face and Gesture Recognition
- March 2024: I joined King Abdullah University of Science and Technology (KAUST) as a Post Doctoral Researcher
- December: I successfully defended my Ph.D. thesis titled Video-Efficient Foundation Models
- November: My Ph.D. thesis is approved by the doctoral committee, with defense set on 8th of December 2023
- September: 'Tubelet-Contrastive Self-Supervision for Video-Efficient Generalization' is accepted as an oral at NCCV
- August: I gave a talk at University of Bonn
- August: I am selected for 'ICCV 2023 Doctoral Consortium'
- July: Our paper 'Tubelet-Contrastive Self-Supervision for Video-Efficient Generalization' is accepted to ICCV
- April 2023: I gave a talk at King Abdullah University of Science and Technology (KAUST)
- August: I attented International Computer Vision Summer School (ICVSS) 2022
- July 2022: Our paper 'How Severe is Benchmark-Sensitivity in Video Self-Supervised Learning?' is accepted to ECCV
- August 2021: Our paper Skeleton-Contrastive 3D Action Representation Learning was accepted at ACM Multimedia
- Octobre 2020: Our paper Feature-Supervised Action Modality Transfer was accepted at ICPR
- May: I joined VIS LAB as a Ph.D. candidate at Univeristy of Amsterdam
- April 2019: Our paper CROSS-MODAL KNOWLEDGE DISTILLATION FOR ACTION RECOGNITION was accepted at ICIP
Publications
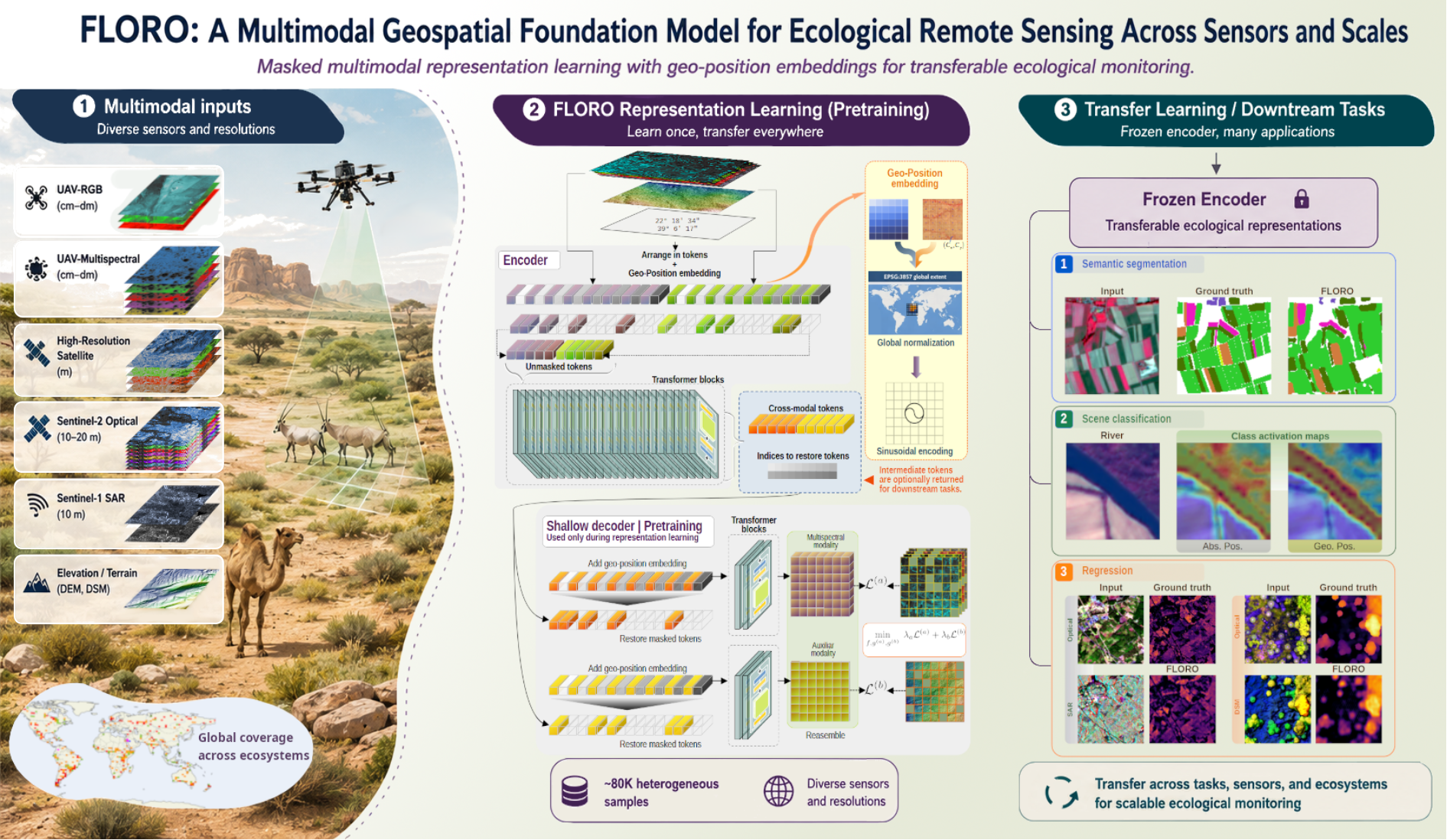 |
FLORO: A Multimodal Geospatial Foundation Model for Ecological Remote Sensing Across Sensors and Scales Jorge L. Rodriguez, Victor Angulo Morales, Areej Alwahas, Mariana Elias Lara, Fida Mohammad Thoker*, Kasper Johansen, Bernard Ghanem, Fernando T. Maestre, Matthew F. McCabe Preprint (Arxiv), 2026. [Webpage] [arXiv] [Code] |
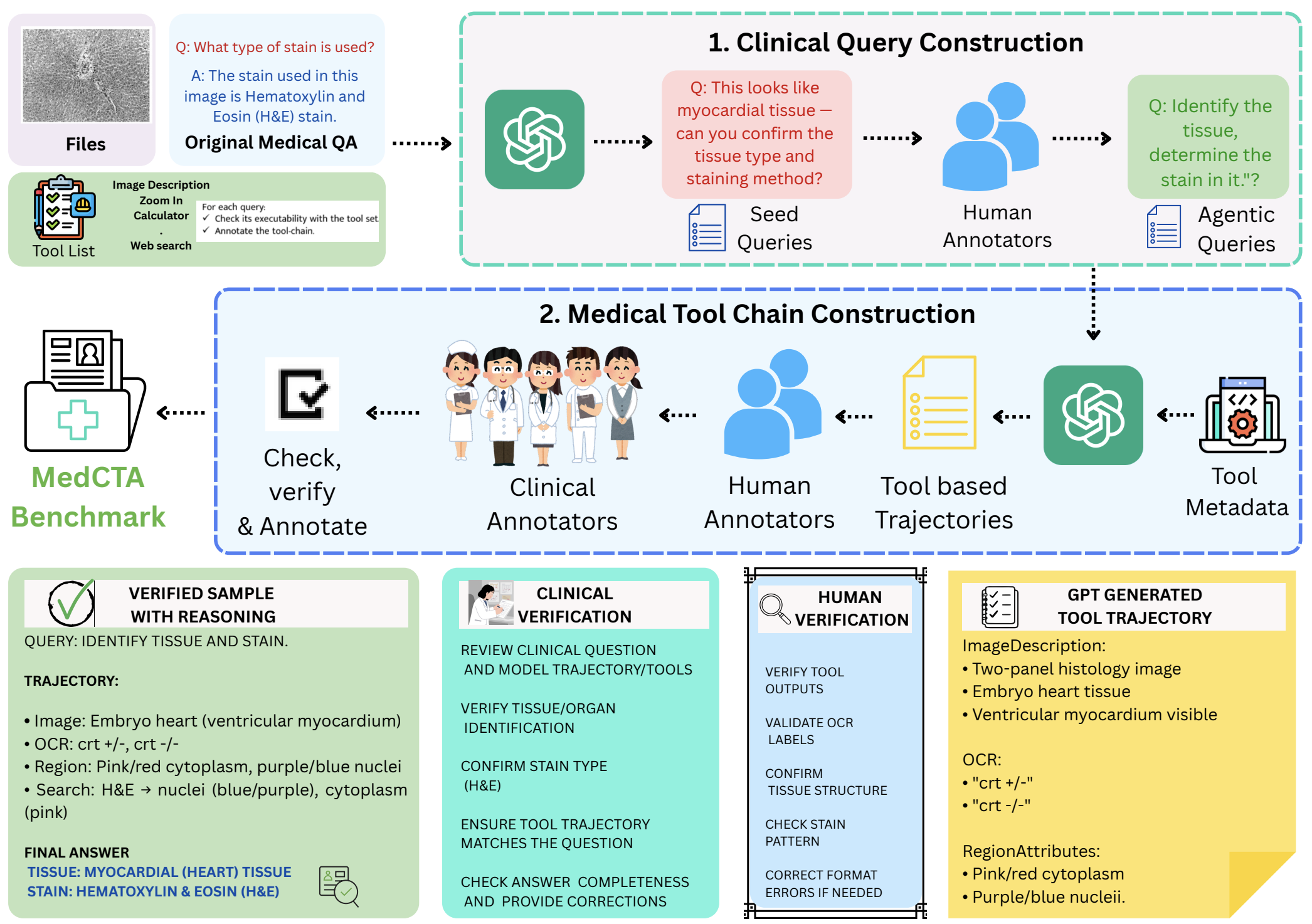 |
MedCTA: A Benchmark for Clinical Tool Agents Tajamul Ashraf, Hyewon Jeong, Fida Mohammad Thoker, Bernard Ghanem Preprint (Arxiv), 2026. [Webpage] [Arxiv] [Code] |
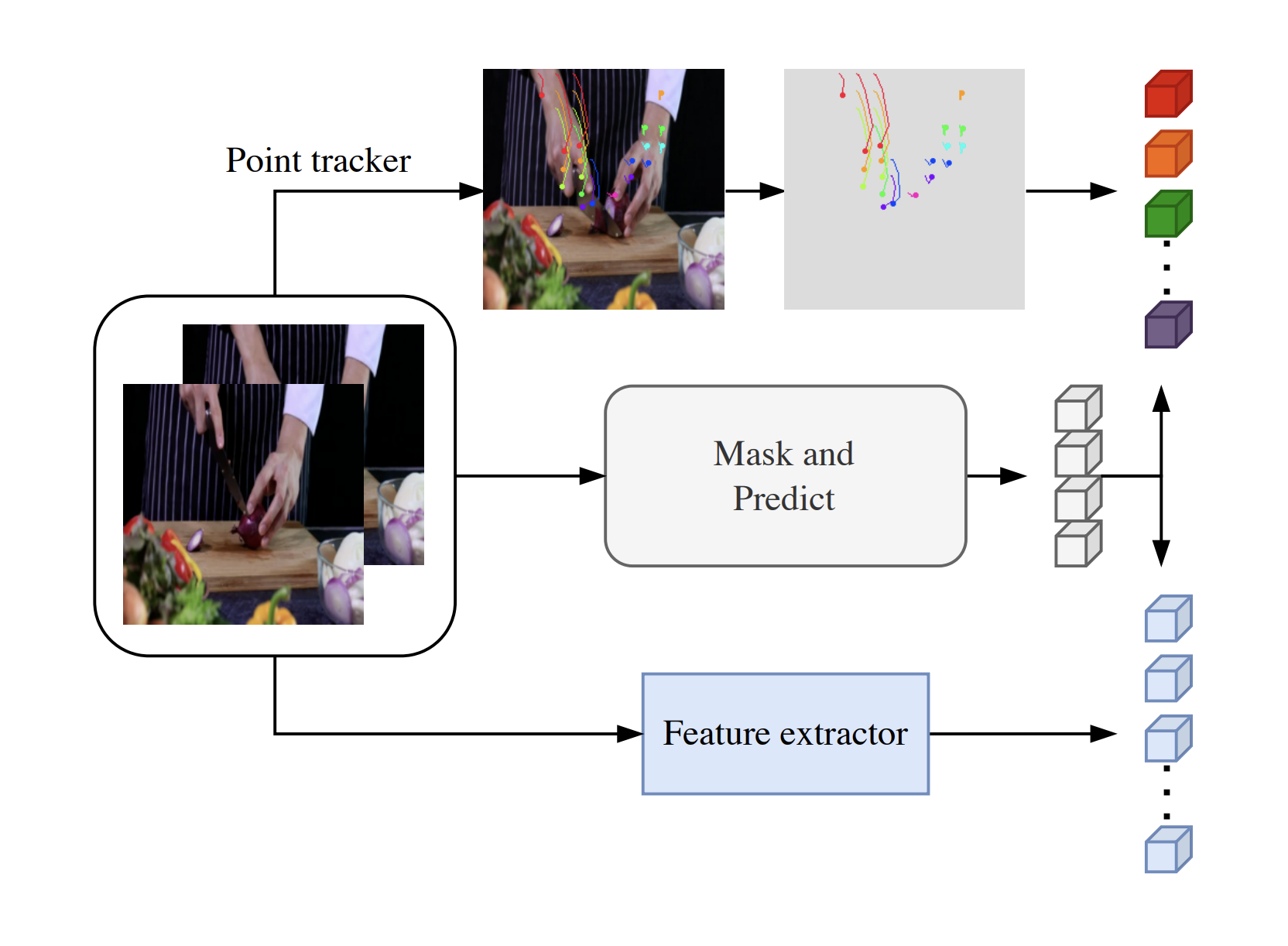 |
TrackMAE: Video Representation Learning via Track Mask and Predict Renaud Vandeghen*, Fida Mohammad Thoker*, Marc Van Droogenbroeck, Bernard Ghanem Conference on Computer Vision and Pattern Recognition (CVPR), 2026. [Webpage] [arXiv] [Code] |
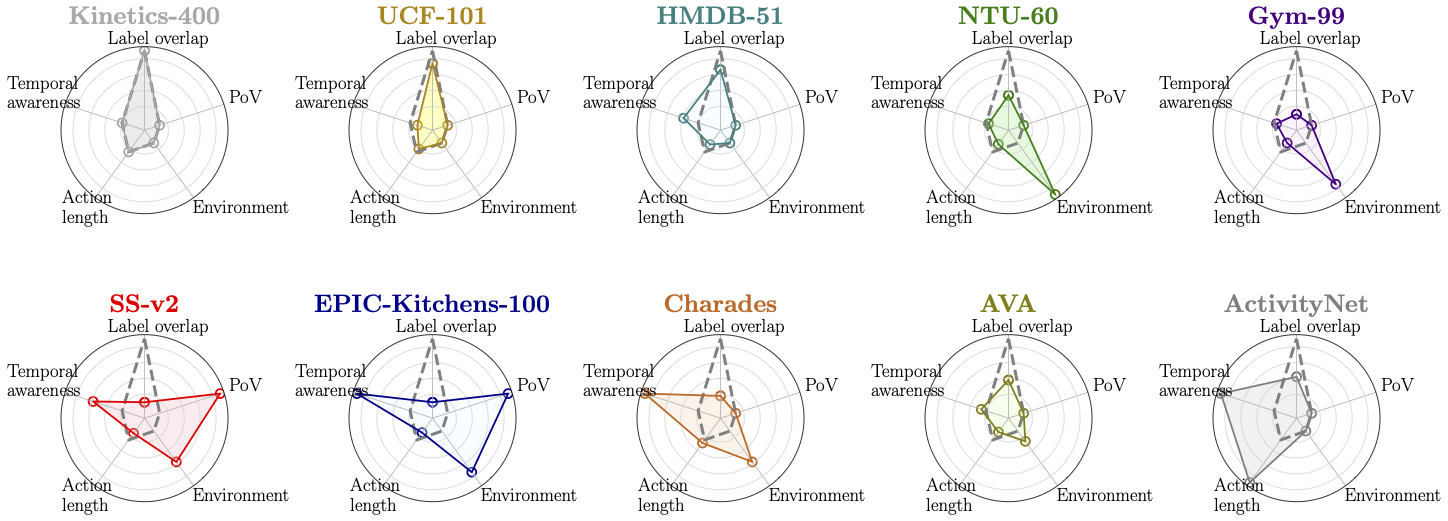 |
SEVERE++: Evaluating Benchmark Sensitivity in Generalization of Video Representation Learning
Fida Mohammad Thoker, Letian Jiang, Chen Zhao, Piyush Bagad, Hazel Doughty, Bernard Ghanem, Cees G. M. Snoek Arxiv (Pre-print), 2025. [Webpage] [arXiv] [Code] |
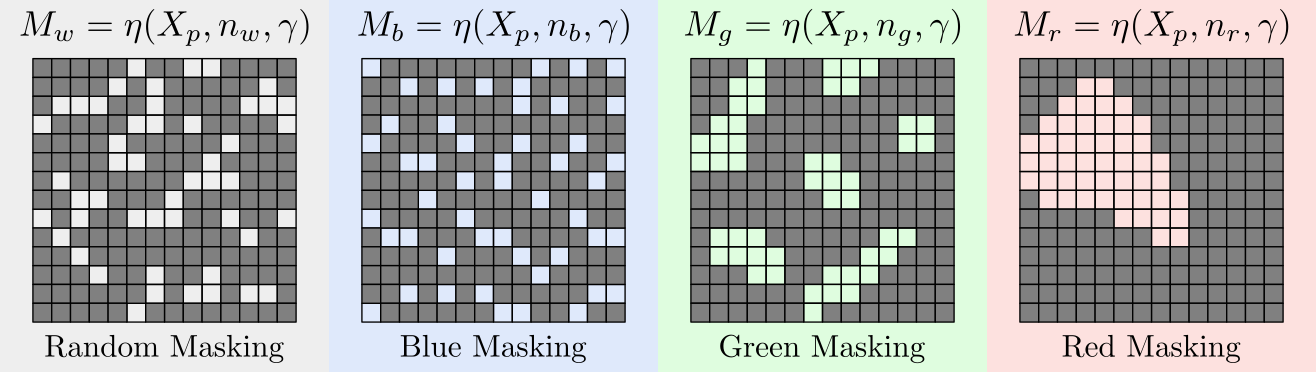 |
Structured-Noise Masked Modeling for Video, Audio and Beyond Aritra Bhowmik,Fida Mohammad Thoker, Carlos Hinojosa, Bernard Ghanem, Cees G. M. Snoek Arxiv (Pre-print), 2025. [Webpage] [arXiv] [Code] |
 |
SMILE: Infusing Spatial and Motion Semantics in Masked Video Learning Fida Mohammad Thoker, Letian Jiang, Chen Zhao, Bernard Ghanem Conference on Computer Vision and Pattern Recognition (CVPR), 2025. [Webpage] [arXiv] [Code] |
 |
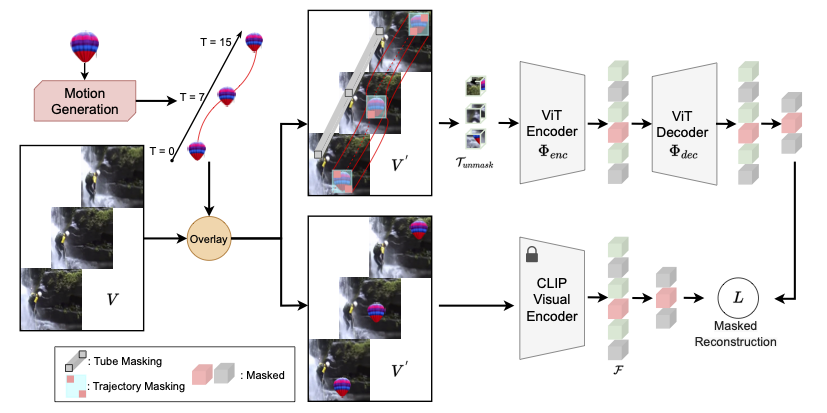
LocoMotion: Learning Motion-Focused Video-Language Representations Hazel Doughty,Fida Mohammad Thoker, Cees Snoek Asian Conference on Computer Vision (ACCV), 2024 (Oral). [Webpage] [arXiv] [Code] |
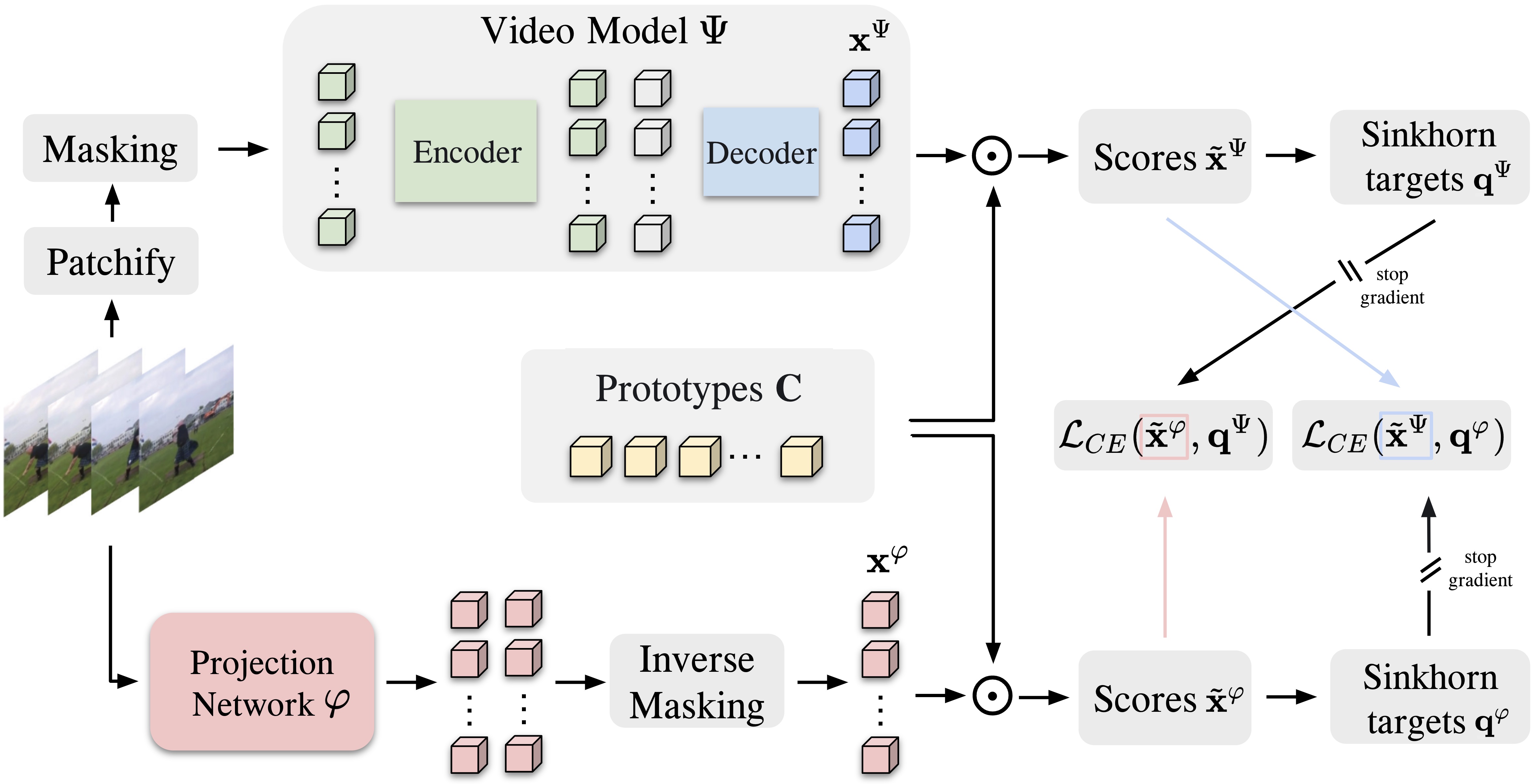 |
SIGMA: Sinkhorn-Guided Masked Video Modeling Mohammadreza Salehi*, Michael Dorkenwald*, Fida Mohammad Thoker*, Efstratios Gavves, Cees G. M. Snoek, Yuki M. Asano European Conference on Computer Vision (ECCV), 2024. [Webpage] [arXiv] [Code] |
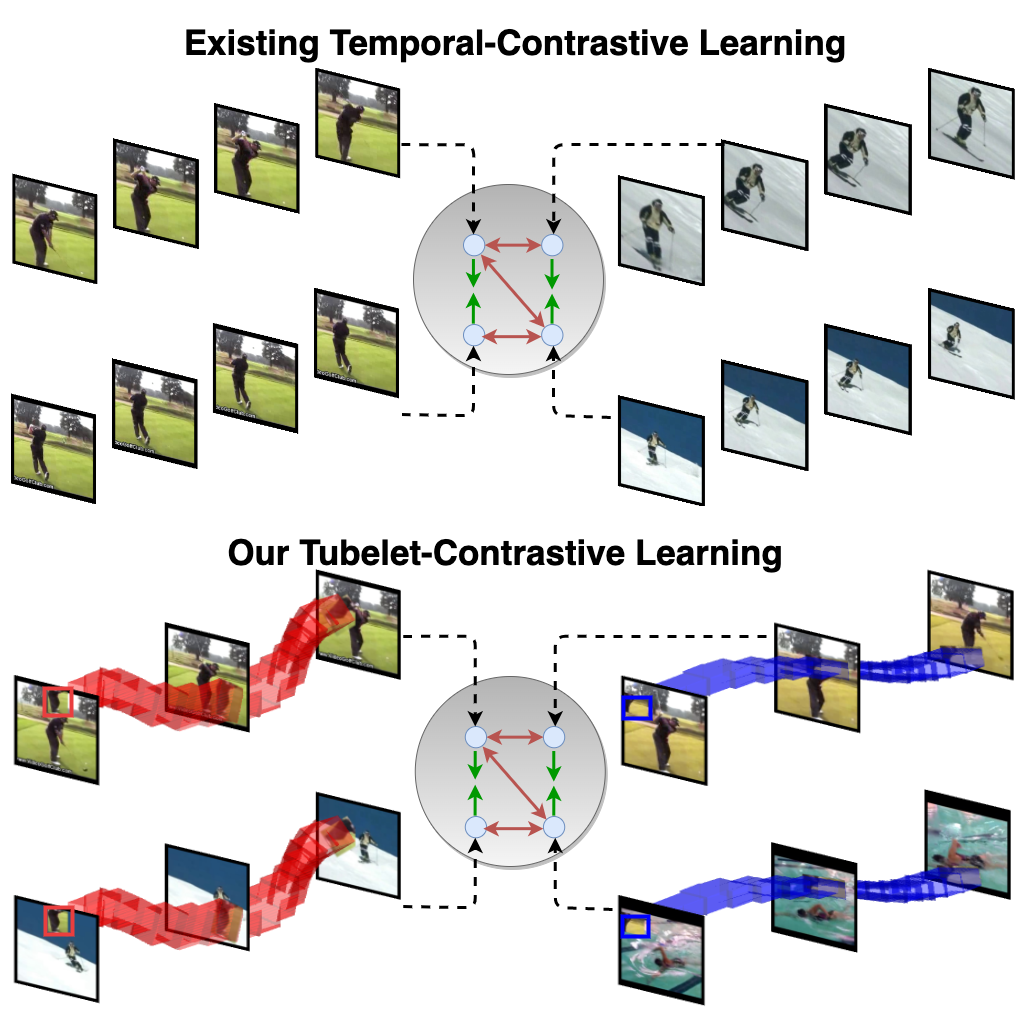 |
Tubelet-Contrastive Self-Supervision for Video-Efficient Generalization Fida Mohammad Thoker, Hazel Doughty, Cees Snoek International Conference on Computer Vision (ICCV), 2023. [Webpage] [arXiv] [Code] |
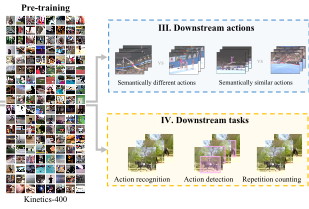 |
How Severe is Benchmark-Sensitivity in Video Self-Supervised Learning? Fida Mohammad Thoker, Hazel Doughty, Piyush Bagad, Cees Snoek European Conference on Computer Vision (ECCV), 2022. [Webpage] [arXiv] [Code] |
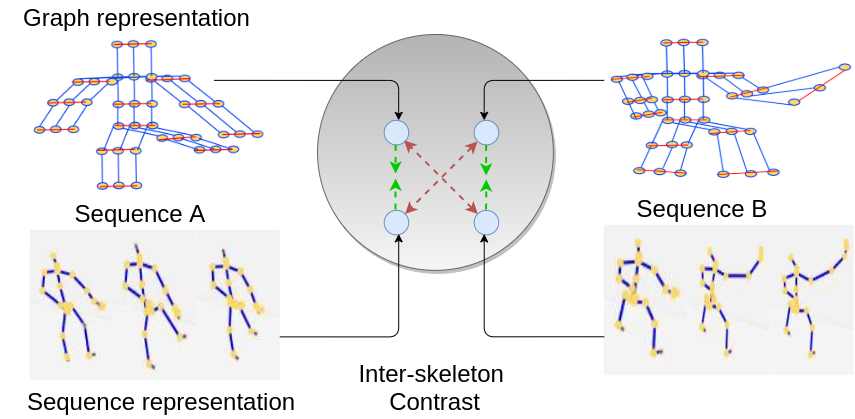 |
Skeleton-Contrastive 3D Action Representation Learning Fida Mohammad Thoker, Hazel Doughty, Cees Snoek ACM International Conference on Multimedia (ACMMM), 2021 [arXiv] [Code] |
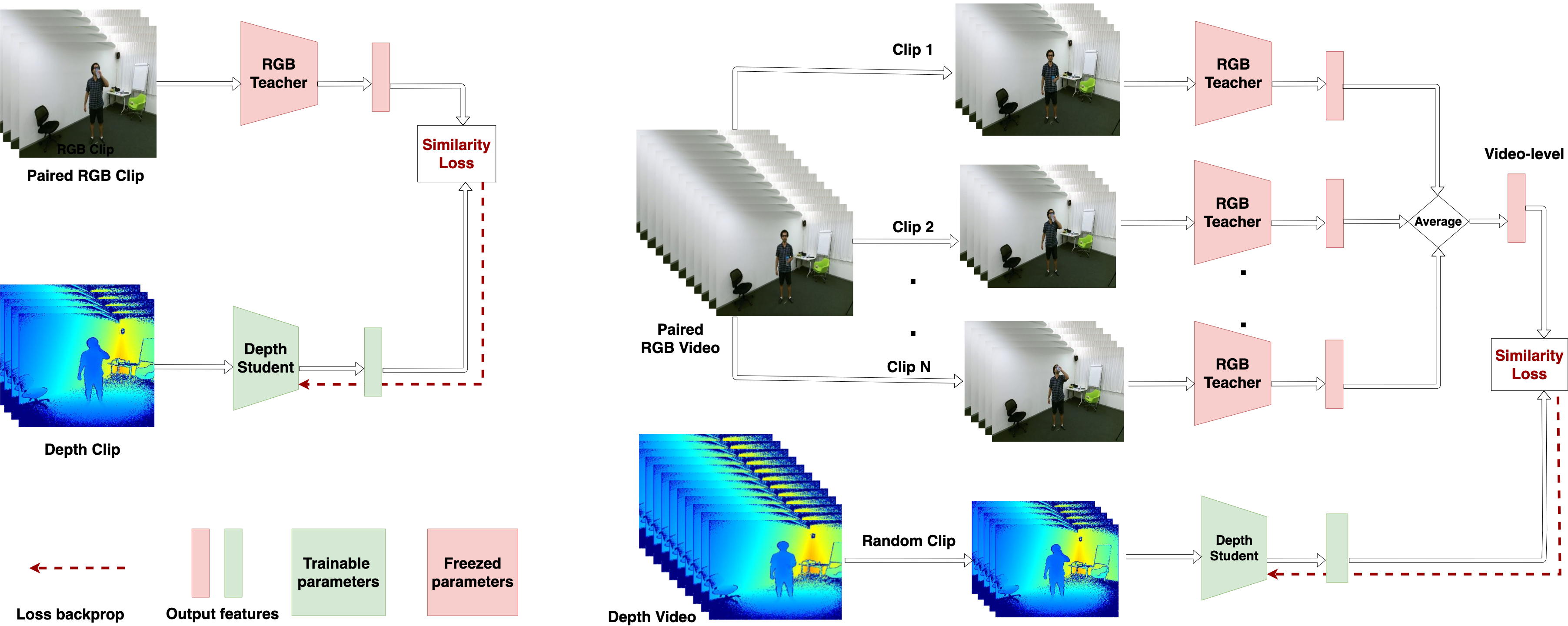 |
Feature-Supervised Action Modality Transfer Fida Mohammad Thoker, Cees Snoek IEEE International Conference on Pattern Recognition (ICPR), 2020 [arXiv] |
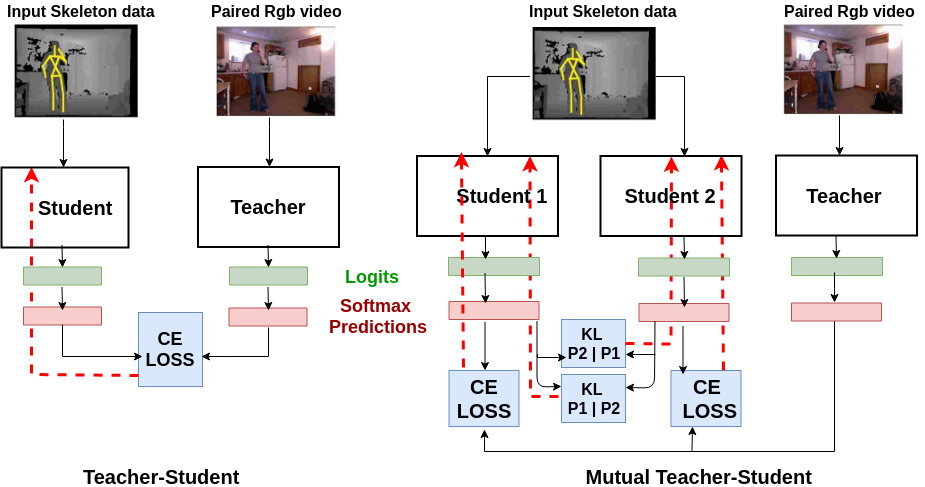 |
CROSS-MODAL KNOWLEDGE DISTILLATION FOR ACTION RECOGNITION Fida Mohammad Thoker, Juergen Gall IEEE International Conference on Image Processing (ICIP), 2019 [arXiv] |
Academic Service
Reviewer: BMVC 2020, CVIU 2021, Nuerips 2021, ICCV 2021, ECCV 2022, ACCV 2022, CVPR 2023, ICCV 2023
Teaching
Teaching Assistant: Deep Learning for Visual Recognition (MSc Computer Science Univerisity of Bonn)
Teaching Assistant: Technical Neural Networks (MSc Computer Science Univerisity of Bonn)